I rewrote tiktoken in Rust and found three bottlenecks hiding at three layers of the stack
There’s a comment buried in OpenAI’s tiktoken source that I keep thinking about:
// I tried using rayon. It wasn't really faster.
If you’ve spent time staring at connection pools, you know what that means. When adding parallelism barely helps, the bottleneck isn’t the work. It’s the thing the work is sharing.
Tokenization sits on the critical path of every LLM API call. Every prompt, every completion, passes through a BPE tokenizer before anything else happens. Most teams treat it as free because tiktoken is fast enough. At scale it isn’t — microseconds per token, billions of tokens a day, real money, real tail latency.
My day job is priority-queue scheduling and job orchestration for ML workloads. Hunting bottlenecks on shared resources is what I do. I wanted to know what was actually in the way.
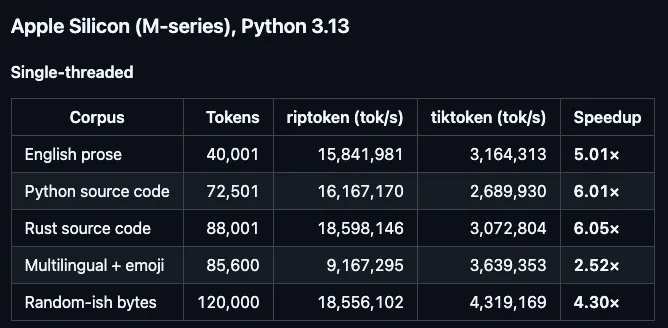
The result is riptoken — a ground-up Rust rewrite with Python bindings, drop-in compatible with tiktoken. Same vocab files, same regex patterns, byte-identical output on all five stock encodings. On an M-series Mac it runs 2.5×–6× faster single-threaded. On a 32-core Sapphire Rapids box, parallel batch encoding runs up to 7× faster at the median — and tiktoken’s p99 batch latency blows out to 9 seconds while riptoken stays under 1.
Three performance wins. Three layers of the stack. Each one invisible until you looked past the abstraction hiding it.
1. A SIMD regex fast path
BPE tokenization has two phases. A regex splits input into chunks — words, punctuation, whitespace. Then each chunk gets merged into tokens via the learned BPE rules. For most inputs, the regex dominates wall-clock time.
tiktoken runs its regex through fancy-regex, which supports lookarounds via backtracking. Rust’s regex crate is SIMD-accelerated and much faster, but it flat-out refuses lookarounds. A DFA can’t backtrack.
The o200k_base pattern has exactly one: \s+(?!\S). In plain English: “if whitespace is followed by a word, leave the last space for the next token.” That’s a behavior, not a syntax feature. Behaviors can be reimplemented without a backtracking engine.
Strip the lookaround. Run the SIMD engine. Reproduce the whitespace rule in a few lines of post-match Rust. Test against tiktoken on five encodings, five corpora. Byte-identical.
That alone doubled single-thread throughput.
2. Pool contention on a hidden DFA cache
Next: encode_ordinary_batch — spray documents across rayon’s thread pool. On my 8-core laptop the scaling looked fine. On the 32-core Sapphire Rapids box, it fell apart: ~95M tokens/sec, roughly 6× over tiktoken. Thirty-two cores buying a 6× speedup is the universal signal that something is serialized.
Inside the regex crate, every match borrows a scratch buffer from a Pool<Cache>. Low concurrency: free. Thirty-two threads hammering the same pool: lock-striped hot spot. The kind of contention that’s invisible in 4-core benchmarks and catastrophic on production hardware.
If you’ve run a database, this shape is familiar. A PostgreSQL connection pool under load: fine when the pool is wide relative to concurrency, disastrous when it isn’t. The fix isn’t to widen the pool. It’s to own the resource per thread.
Give each thread its own Regex clone. No sharing, no pool, no contention:
- Before (per-thread cloning off): ~95M tokens/sec, ~6× over tiktoken
- After (per-thread cloning on): ~35M median tok/s, ~4–7× over tiktoken at median
But the median hides the real story. tiktoken’s Pool<Cache> creates unpredictable tail-latency spikes — on 32 cores, its p99 batch time hits 9.3 seconds on multilingual text. riptoken’s p99: 777 ms. Same input, same thread count, 12× more predictable.
The throughput win from per-thread cloning is real. The stability win is bigger. Regex is Clone and cheap to clone. The contention lives entirely inside the compiled matcher’s scratch pool, and the type system gives you no hint it’s there.
3. Killing cold-start with compile-time DFAs
The SIMD path was fast on warm runs. First call was a different story.
Rust’s regex crate uses a lazy DFA — states materialize on demand as the engine sees new input. For o200k_base, with its dozens of Unicode property classes spanning CJK, Latin, Arabic, and more, the first call on 141K characters of Japanese text cost ~55 ms. Warm calls: ~8 ms. tiktoken: a consistent ~20 ms. riptoken was slower on cold start.
regex doesn’t let you force all states upfront. But regex-automata — the lower-level crate underneath it — does. Build a fully-materialized dense DFA: every state computed once, stored in a flat table, never touched again at search time.
The question: how big? Unicode patterns can blow up.
| Pattern | Dense DFA | Build time |
|---|---|---|
| gpt2/r50k | 1.6 MB | 80 ms |
| cl100k | 3.7 MB | 133 ms |
| o200k | 11.0 MB | 1.5 s |
All under 20 MB — viable. But 1.5 seconds to build o200k at runtime defeats the purpose.
The fix: move it to compile time. A build.rs script pre-compiles each DFA, serializes the forward and reverse automata to byte arrays, embeds them in the binary via include_bytes!. At runtime, stock patterns get detected by exact string match and deserialized from the embedded bytes. Near-zero cost.
| Metric | Before (lazy) | After (precompiled) |
|---|---|---|
| o200k construction | ~200 ms | ~210 ms |
| First encode (141K CJK) | ~55 ms | ~5.7 ms |
| Second encode | ~8 ms | ~5.7 ms |
Construction unchanged. Cold-start gone. Every call is the fast path.
One more thing: the dense DFA has no mutable state. No scratch buffers, no Pool<Cache>. A single instance shared across all threads, zero clones. The per-thread clone pool that fixed parallel scaling? For stock patterns, it’s gone entirely. The abstraction that required per-thread ownership was replaced by one that doesn’t.
The pattern
A regex engine that refuses lookarounds — until you realize the lookaround is a behavior you can reimplement. A thread pool that scales linearly — until every thread is serializing on a hidden scratch buffer. A warm path that’s fast — until “warm” assumes someone already paid the cold-start.
Each fix was simple. Finding where to look was the work.
Correctness
A performance writeup without a correctness section is fiction.
riptoken is byte-identical to tiktoken on all five stock encodings (gpt2, r50k_base, p50k_base, cl100k_base, o200k_base). A parity suite of 61 tests runs both encoders across English prose, Python source, Rust source, multilingual + emoji, and random bytes. A separate internet parity test pulls 23.8 MB of real text — Gutenberg, Wikipedia in five languages, Linux kernel source — and compares every token.
Every optimization was developed under these tests, not validated after. If the output were almost the same, none of the speed would matter. Almost-right tokenization means wrong logits means wrong completions.
Try it
MIT-licensed on GitHub at github.com/daechoi/riptoken. Rust crate + Python package.
import riptoken
enc = riptoken.get_encoding("o200k_base")
enc.encode_ordinary("hello world")Same API as tiktoken.get_encoding. Same vocab files. Same output. If tiktoken is already installed, riptoken reuses its cache.
Happy to trade notes with anyone working on inference-path performance.